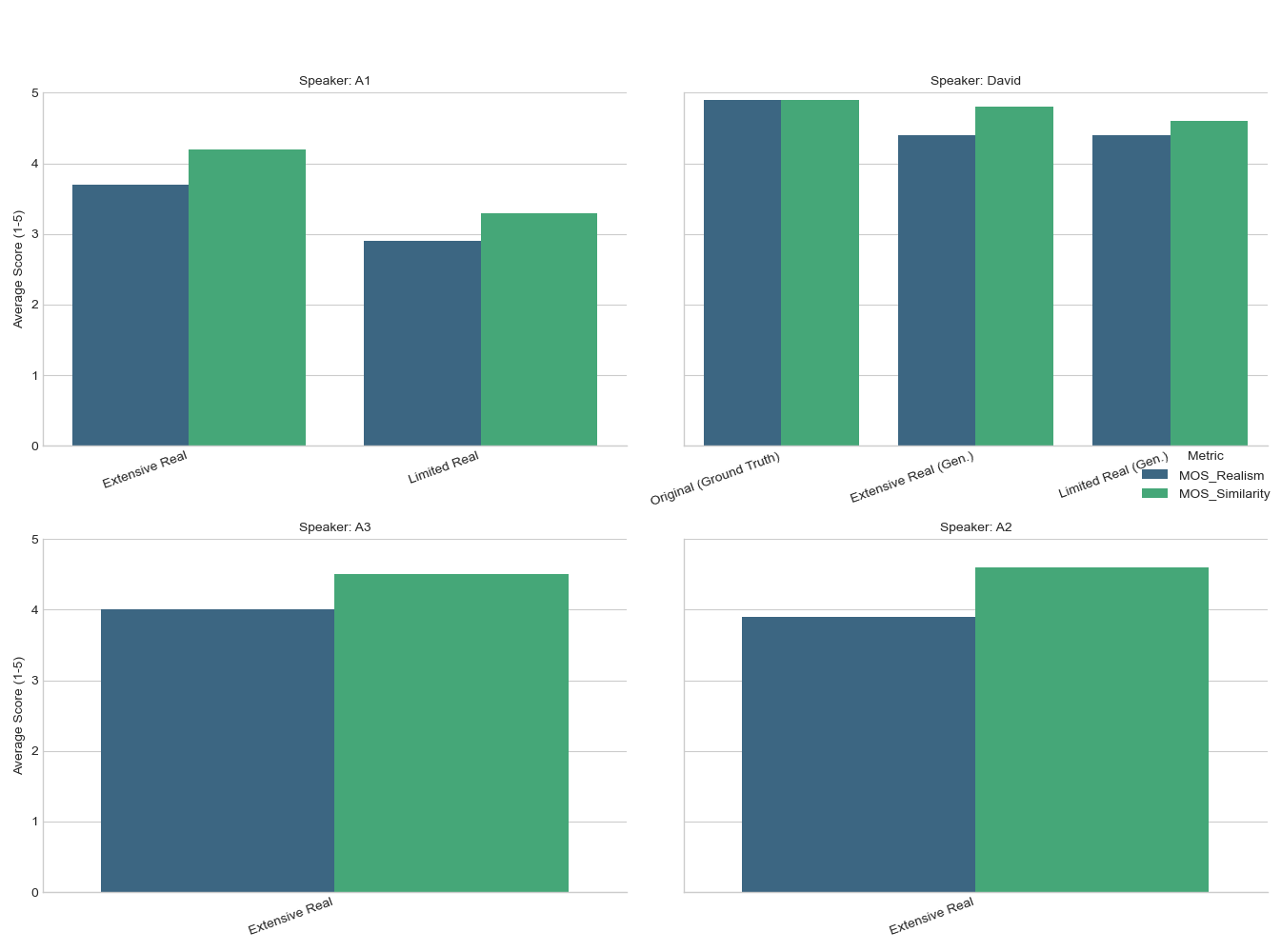
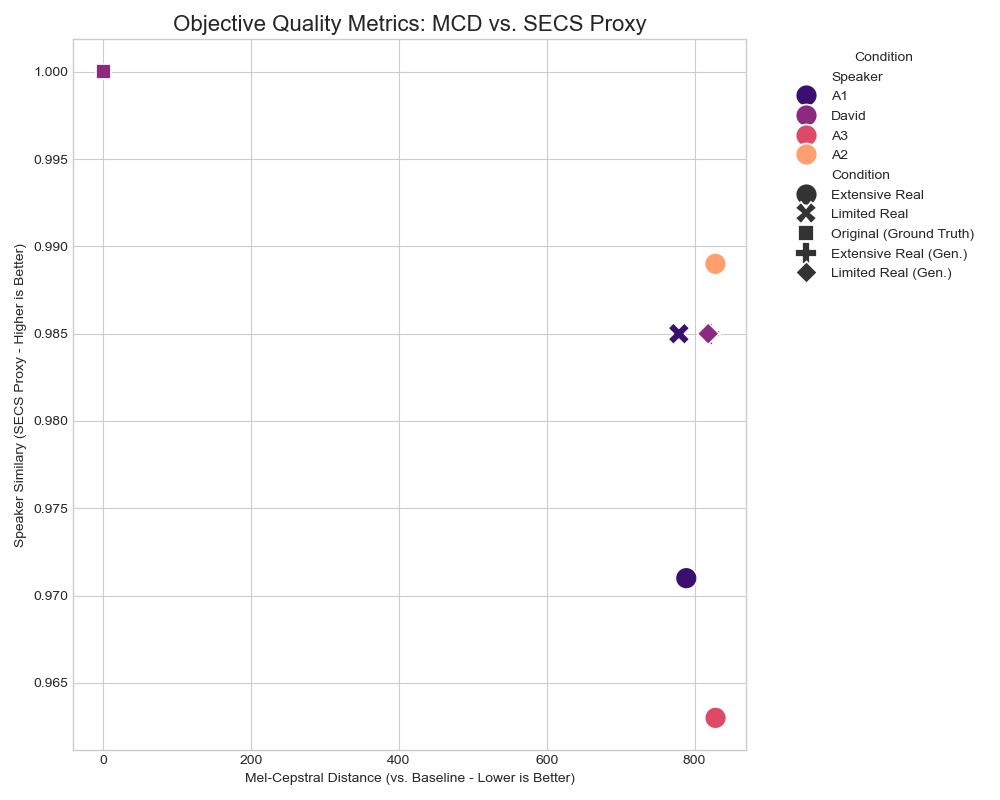
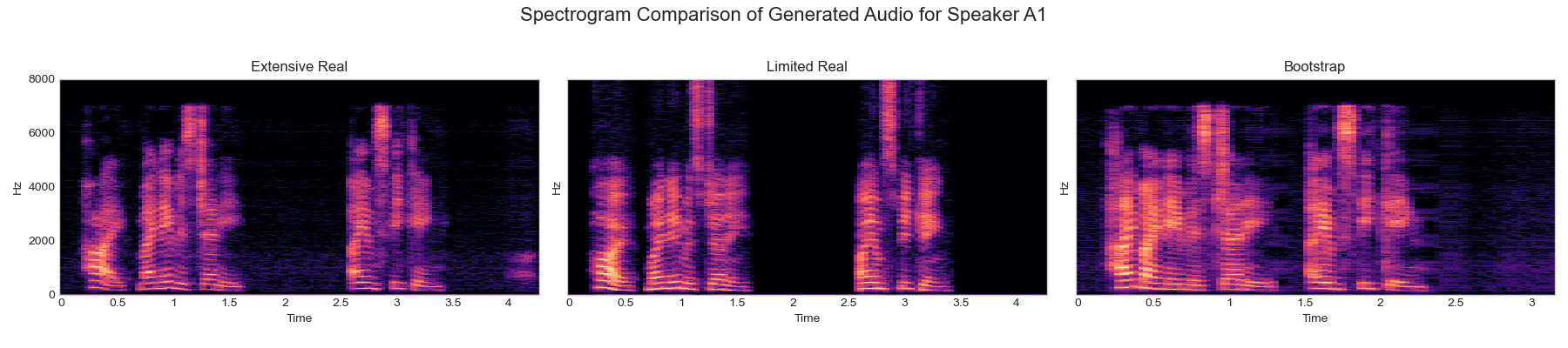
Exploratory Data Analysis
Before training our models, we analyzed our source datasets to understand their core characteristics. This essential step involved examining clip durations, visualizing audio as spectrograms, and testing simple data augmentations.
Self-Collected Data Analysis
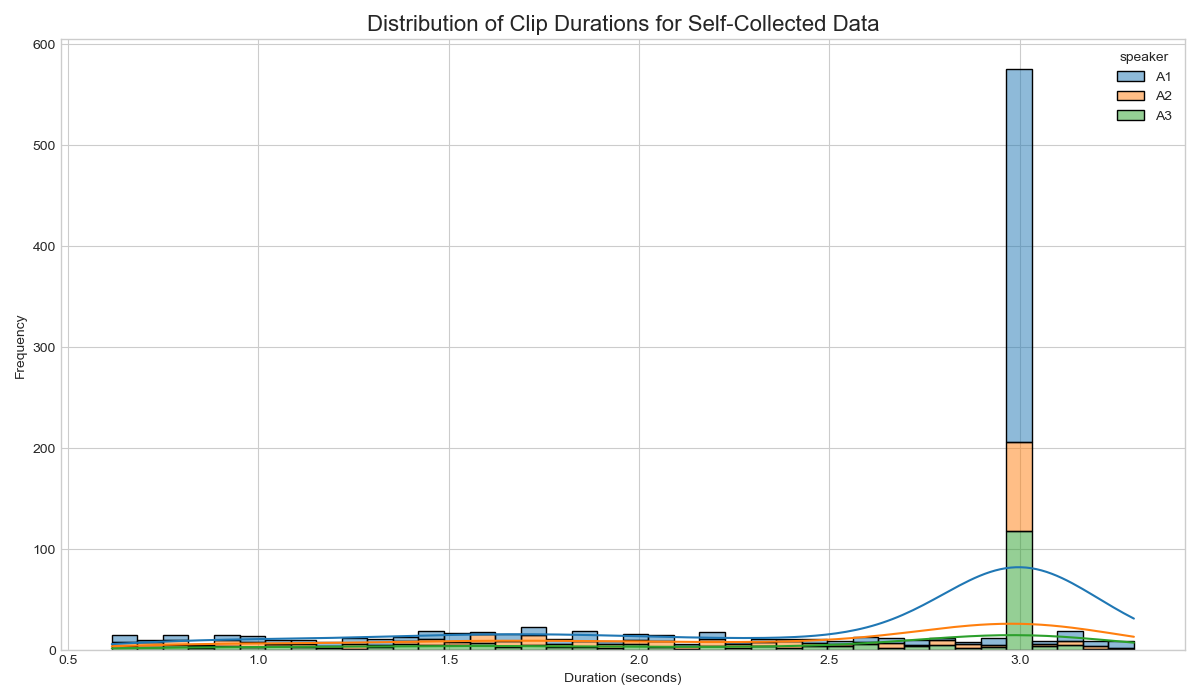
Figure: This distribution of clip durations from our self-recorded data confirms that most clips are between two and ten seconds long, which is ideal for training.
Public Dataset Analysis
We performed the same analysis on the public LibriTTS and LJSpeech datasets to benchmark their properties and demonstrate augmentation techniques.
LibriTTS Dataset
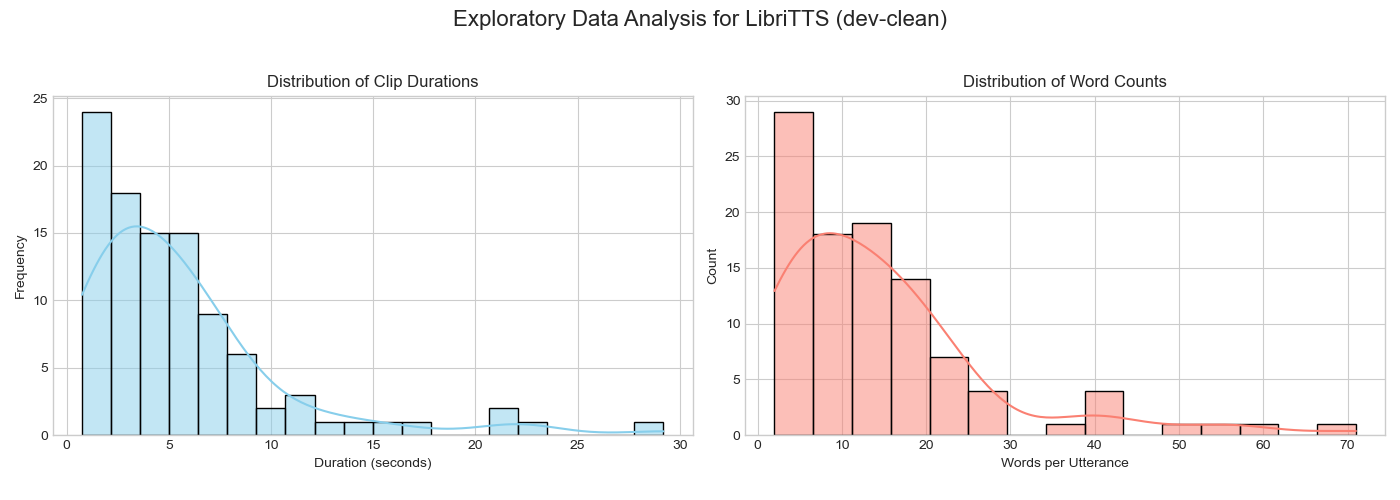
Figure: Clip duration and word count for LibriTTS samples.
Audio Augmentation Demo
Original
Pitch Up (+2 Semitones)
Pitch Down (-2 Semitones)
LJSpeech Dataset
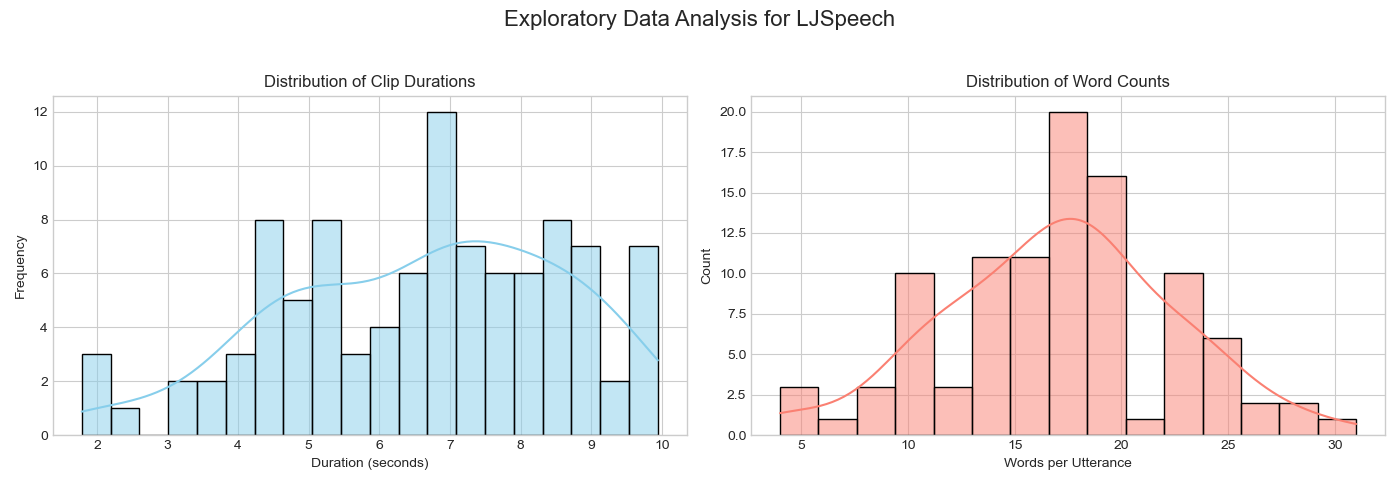
Figure: Clip duration and word count for LJSpeech samples.
Audio Augmentation Demo
Original
Pitch Up (+2 Semitones)
Pitch Down (-2 Semitones)